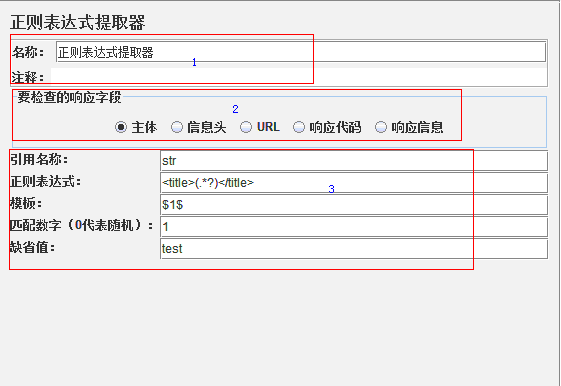
位置1:名称及注释 位置2:正则表达式提取内容的范围。(关于各字段的详细说明请查阅协议的相关说明) 位置3:正则表达式提取的相关设置
- 引用名称:其他地方引用提取值的变量名称,如填写的是:str,具体的引用方式是${str}
- 正则表达式:提取内容的正则表达式【稍注意一下:()表示提取,对于你要提前的内容需要用小括号括起来】
- 模板:用$$引用起来,如果在正则表达式中有多个提取表达式(多个括号括起来的东东),则可以是$1$,$2$等等,表示解析到的第几个值给str,正则表达式的提取模式,值从1开始,值0对应的是整个匹配的表达式 如对于表达式s(.*) 值0对应str,值1对应tr
- 匹配数字(0代表随机):0代表随机,-1代表所有,其余正整数代表将在已提取的内容中,第几个匹配的内容。
- 缺省值:正则匹配失败时,取的值
(1)引用名称:下一个请求要引用的参数名称,如填写title,则可用${title}引用它。
(2)正则表达式:
():括起来的部分就是要提取的。
.:匹配任何字符串。
+:一次或多次。
?:不要太贪婪,在找到第一个匹配项后停止。
(3)模板:用$$引用起来,如果在正则表达式中有多个正则表达式,则可以是$2$$3$等等,表示解析到的第几个值给title。如:$1$表示解析到的第1个值
(4)匹配数字:0代表随机取值,-1代表全部取值,通常情况下填1
(5)缺省值:如果参数没有取得到值,那默认给一个值让它取。
关于正则表达式的举例说明:
1、提取单个字符串:
假如想匹配Web页面的如下部分:name = "file" value = "readme.txt">并提取readme.txt。一个合适的正则表达式:name = "file" value = "(.+?)">。 ():封装了待返回的匹配字符串。 .:匹配任何单个字符串。 +:一次或多次。 ?:不要太贪婪,在找到第一个匹配项后停止。 2、提取多个字符串: 假如想匹配Web页面的如下部分:name = "file.name" value = "readme.txt">并提取file.name和readme.txt。一个合适的正则表达式:name = "(.+?)" value = "(.+?)"。这样就会创建2个组,分别用于$1$和$2$比如:
引用名称:MYREF
模板:$1$$2$如下变量的值将会被设定:
MYREF: file.namereadme.txt MYREF_g0: name = "file.name"value = "readme.txt" MYREF_g1: file.name MYREF_g2: readme.txt在需要引用地方可以通过:${MYREF}, ${MYREF_g1进行使用。